Background
I have finished my structured review of the validity of BLEU (which reviews previous research papers which measure how well BLEU correlates with human evaluations). This will be published in Computational Linguistics journal in Sept 2018, as a squib. It has three main messages:
- Use BLEU with caution when evaluating MT systems (it should not be used on its own to test scientific hypotheses). Dont use it for anything else (such as NLG).
- We need better validation studies of BLEU (and other metrics), which for example look at correlation with real-world task effectiveness.
- NLP (as well as medicine) can benefit from systematic reviews and meta-analyses.
There were a number of “secondary” points which I had to drop from the paper because of space limitations. I hope to cover some of these in my blog over the next few months, starting with the puzzling (at least to me) observation that the correlation between BLEU and human evaluations seems to be increasing with time (thanks to Mike White for first pointing out to me that my data suggested this was happening). Which is weird; since BLEU hasnt changed since it was introduced in 2002, how can its correlation with human evaluations change over time?
BLEU-Human Correlation is Increasing
The below graph shows the median correlation between BLEU and human evaluations of MT systems (ie, the context where BLEU works best), for all such studies published in a particular year. For example, in 2002, the only such correlations presented were in the original BLEU paper published in 2002. This paper presented two correlations between BLEU and human evaluations: 0.99 when the human evaluators were monolingual and 0.96 when the human evaluators were bilingual. Hence the median BLEU-human correlation for 2002 was 0.975 (for two values, median is the same as mean). I have added a best fit regression line to the data.
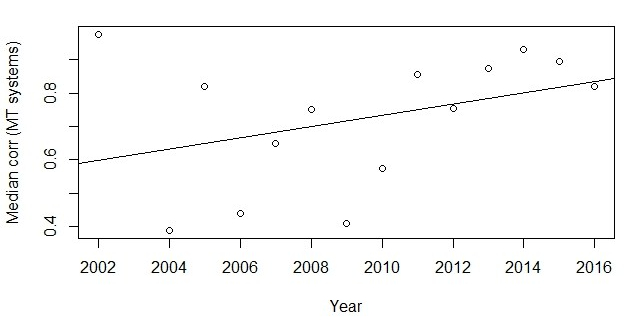
As can be seen from the regression line, although the 2002 paper was an outlier (and 2002 still has the highest median correlation of any year), overall the correlation between BLEU and human evaluations of MT systems has increased over time. This effect is robust, in that I see it in other statistical analyses as well as the above one; I also see it if I look at specific tasks such as translation of news articles from German to English.
Caveat: We only see this effect if we look at correlations between BLEU and human evaluations of systems. Some studies have instead looked at the correlation between BLEU and human evaluations of individual texts (sometimes called segments). These correlations are considerably worse, and do not seem to be improving over time.
Why is BLEU-Human Correlation Increasing?
It seems somewhat bizarre that the correlation between BLEU and human evaluations of MT systems is increasing. After all, BLEU has not changed since it was introduced. There have been improvements in pre-processing steps such as tokenisation, but it seems unlikely that these changes could have caused this increase.
If the change in BLEU-human correlation is not due to changes in BLEU, then it could be due to changes in the human evaluations, or to changes in the systems being evaluated. More specifically, below are three possible explanations for the increase.
Better human evaluations: Perhaps the change is due to a change in the nature of the human evaluations (which BLEU is correlated against). In particular, perhaps these human evaluations are being done better, with less noise. Other things being equal, less random noise in the human evaluations should increase correlations with BLEU.
If this is the case, then increasing correlations are a positive sign of progress in the field (better human evaluations).
Changes in quality of systems evaluated: Perhaps the change is due to the changing nature of the systems being evaluated. In particular, the quality of the NLP systems being evaluated has increased, as technology gets better. It seems likely that the correlation between BLEU and human evaluations depends on the overall quality of the system being evaluated. Perhaps, for example, BLEU-human correlations are low for really bad and really good systems, but higher for systems which produce moderate quality output. If so, then the change in BLEU-human correlation could just reflect the change in the quality of the systems being evaluated.
If this is the case, then this is a positive sign, showing that our systems are getting better.
Researchers focus on approaches that BLEU likes: A more worrying explanation is that the change is because researchers have given up on investigating NLP approaches that get poor BLEU scores but good human evaluations, because they cannot publish such work or get funded. We know that BLEU has biases, for example against rule-based systems; if rule-based system R and statistical/neural system S get similar human evaluations, then BLEU will almost certainly give a higher score to S than to R. If researchers are indeed being guided by BLEU’s biases in this way, then we would expect correlations between BLEU and human evaluations to increase, because fewer of the systems being evaluated would have a major mismatch between their BLEU and human evaluation (low BLEU score but high human evaluation).
If this is the case, then this is a bad sign; it means that the field is ignoring potentially useful approaches just because they get poor BLEU scores, even if other evidence suggests that these approaches could be effective.
Conclusion
Correlations between BLEU and human evaluations of MT systems are increasing, despite the fact that BLEU has not changed. This is something of a mystery. It could be a good sign, showing higher-quality human evaluations and/or NLP systems. Or it could be a bad sign, showing that the field is ignoring promising approaches because BLEU is biased against them.
It would be good if we could resolve this mystery!

My hypothesis: it’s a a side effect of fewer rule-based MT systems being entered into the WMT shared tasks. They usually had reasonable human ratings, but abysmal BLEU scores.
LikeLiked by 1 person
That could be tested, no? Measuring if there is a trend in human ratings, becoming worse as more MT systems are being used.
LikeLike
SMT systems are optimized for BLEU via MERT though admitted there’s only 12 or so parameters to tune. In NMT, some people do discriminative training or other BLEU optimization, but many systems are trained for perplexity. Systems optimized for perplexity have not directly gamed BLEU and therefore should show better correlation between BLEU and human judgements.
LikeLike
I received an interesting comment from @marian_nmt, who wondered if the increase in BLEU-human correlation could be due to a change in the nature of the reference texts used by BLEU. In 2018, human translators use MT technology to help them (eg, in post-editing), which means that “human-authored” reference texts are partially created by an MT system (this happened in 2008 as well, but it happens more in 2018). So reference texts should be more similar to 100% MT texts.
This impacts correlations in part because it reduces the variability of reference texts, which is a type of statistical “noise” in this context. It also reduces the chance of a reference text being an “innovative” translation which is very different from anything an MT system might produce, and hence of a good MT output getting a poor BLEU score because the reference text is very different.
LikeLike