Adarsa Sivaprasad is doing a PhD with me on the topic of generating linguistic explanations of simple models to members of the general public, especially of probabilistic information. This is part of the NL4XAI project. Adarsa will be presenting a paper at the EACL workshop on uncertainty-aware NLP, on Linguistically Communicating Uncertainty in Patient-Facing Risk Prediction Models. I think this is very interesting and important research, and I encourage interested people to read the paper and get in touch with Adarsa.
Of course it is difficult to effectively communicate probabilities to the general public, as numerous people have said; the Winton Centre has a good collection of relevant resources and links. Most previous work has looked at communicating single probabilities. However, this is not sufficient in many cases. Complexities include communicating statistical confidence as well as likelihood, communicating time-series of probabilities, and responding to concerns about missing features; I describe these below (see Adarsa’s paper for more details). I focus on the challenges, not solutions.
Likelihood and Confidence
Adarsa started off looking at decision trees which predict risk of heart disease. When a user consults such a model, the software can pinpoint the decision-tree lead node which applies to the user, which will contain NumPos positive samples (people in the training data with these characteristics who developed heart disease) and NumNeg negative samples (people in the training data who did not develop heart disease).
When interpreting these numbers, the most obvious thing to look it is (NumPos) / (NumPos+NumNeg), ie the fraction of samples in the node which are positive; we can call this the “likelihood” of getting the disease. However, if the number of samples is small, then we do not have much statistical confidence in this likelihood; eg if there is only one sample in the node and it is positive, then the likelihood is 100%, but we have little statistical confidence in this because it is based on a tiny sample.
We can compute statistical confidence using a chi-square test, but the challenge is communicating this to the user. Saying “we have low confidence that you have a high risk of developing heart disease” literally describes the situation, but will probably just confuse most members of the public.
Time-series of probabilities
Adarsais is currently looking at communicating success probabilities to women who are thinking of IVF treatment, working with a team at Aberdeen’s medical school which has developed and deployed a predictive tool for this (OPIS). The output of the tool is not a single probability, but rather a time series showing the probability of success (having a baby) after 1, 2, 3, 4, 5, or 6 IVF cycles; see below example from the paper.
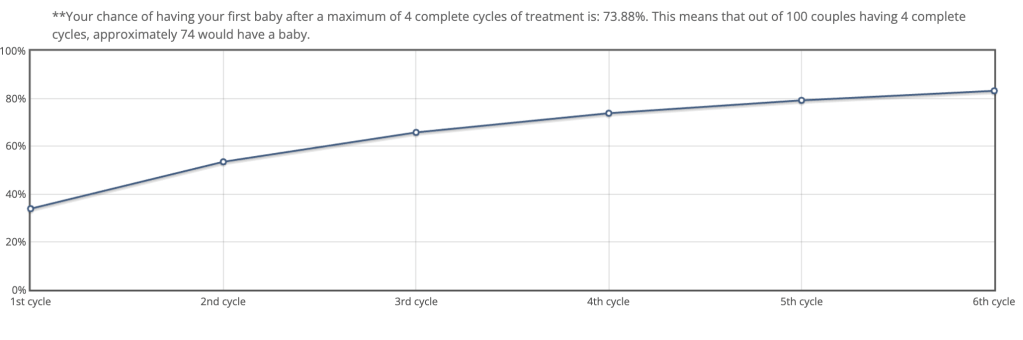
If a single probability is hard to understand, then a time-series of probabilities is going to be even harder. Adarsa looked at user feedback on OPIS, and 24% of the people who provided feedbakc said they could not understand what they were being told.
So again we have a communication challenge; how can we communicate a time-series of probabilities to users who may struggle to understand a single probability?
Unknown Knowns
Another common theme in the OPIS user feedback is questions about missing features. OPIS is trained on a large fertility data set from UK HFEA. Users must enter their patient data explicitly (it isn’t automatically extracted from a patient record), so the tool focuses on features which have a major impact on success.
Anyways, many users said that they had health information which they believed was relevant to IVF success (high BMI, smoking, various medical conditions, etc), but which was not entered into OPIS. They asked if they could believe/trust OPIS’s predictions, since it had ignored these features.
Answering this questions requires understanding the HFEA data set and how the OPIS model was built; ie, we cannot give a good explanation just based on the model itself!
- Some features were present in the HFEA data but had little impact, so they were dropped from OPIS; we can tell users that OPIS predictions are still valid despite ignoring such features.
- Other features (especially unusual medical conditions) were not included in the HFEA data, so ignoring them may mean that the predictions are not accurate.
- BMI is an interesting case because it is partially present in the HFEA data, but primarily has an impact when it is large. However, the UK NHS does not provide IVF treatment to people with high BMI, so OPIS ignores it. Some private IVF providers cater to high-BMI individuals, so whether BMI is relevant depends in part on the intentions of the user (NHS vs private treatment).
Such questions are very important to users, we need better ways of responding to them.
Next steps
Of course Adarsa’s ultimate goal is to build systems which address at least some of the above challenges. I suspect she will use a dialogue system since it is better suited to answering complex questions, especially when further information is needed from the user. The next step is to work more closely with users (after getting relevant ethical approvals) on challenges and potential solutions; people who are considering or have undergone IVF are usually very committed, which hopefully means that will give us good feedback.

2 thoughts on “Communicating uncertainty to non-experts”